1.概述
在存储业务数据的时候,随着业务的增长,Hive 表存储在 HDFS 的上的数据会随时间的增加而增加,而以 Text 文本格式存储在 HDFS 上,所消耗的容量资源巨大。那么,我们需要有一种方式来减少容量的成本。而在 Hive 中,有一种 ORC 文件格式可以极大的减少存储的容量成本。今天,笔者就为大家分享如何实现流式数据追加到 Hive ORC 表中。
2.内容
2.1 ORC
这里,我们首先需要知道 Hive 的 ORC 是什么。在此之前,Hive 中存在一种 RC 文件,而 ORC 的出现,对 RC 这种文件做了许多优化,这种文件格式可以提供一种高效的方式来存储 Hive 数据,使用 ORC 文件可以提供 Hive 的读写以及性能。其优点如下:
减少 NameNode 的负载
支持复杂数据类型(如 list,map,struct 等等)
文件中包含索引
块压缩
...
结构图(来源于 Apache ORC 官网)如下所示:
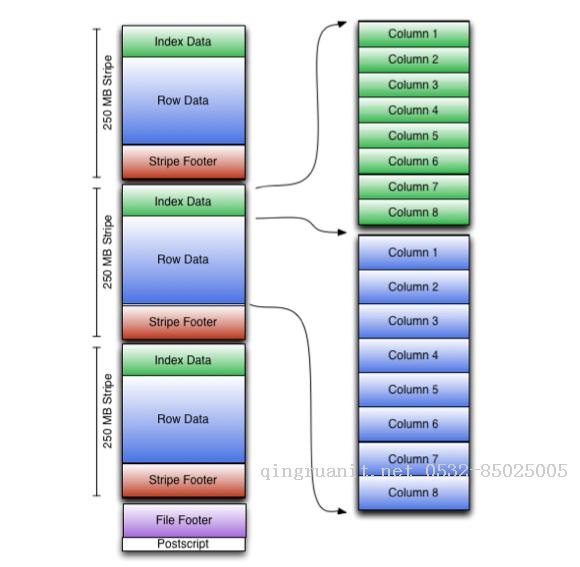
这里笔者就不一一列举了,更多详情,可以阅读官网介绍:[入口地址]
2.2 使用
知道了 ORC 文件的结构,以及相关作用,我们如何去使用 ORC 表,下面我们以创建一个处理 Stream 记录的表为例,其创建示例 SQL 如下所示:
create table alerts ( id int , msg string )
partitioned by (continent string, country string) clustered by (id) into 5 buckets
stored as orc tblproperties("transactional"="true"); // currently ORC is required for streaming需要注意的是,在使用 Streaming 的时候,创建 ORC 表,需要使用分区分桶。
下面,我们尝试插入一下数据,来模拟 Streaming 的流程,代码如下所示:
延伸阅读
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式