Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页
工作流程分析
以初始的URL初始化Request,并设置回调函数,当该request下载完毕并返回时,将生成response,并作为参数传给回调函数. spider中初始的requesst是通过start_requests()来获取的。start_requests()获取 start_urls中的URL,并以parse以回调函数生成Request
在回调函数内分析返回的网页内容,可以返回Item对象,或者Dict,或者Request,以及是一个包含三者的可迭代的容器,返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数
在回调函数内,可以通过lxml,bs4,xpath,css等方法获取我们想要的内容生成item
最后将item传递给Pipeline处理
我们以通过简单的分析源码来理解
我通常在写spiders下写爬虫的时候,我们并没有写start_requests来处理start_urls中的url,这是因为我们在继承的scrapy.Spider中已经写过了,我们可以点开scrapy.Spider查看分析
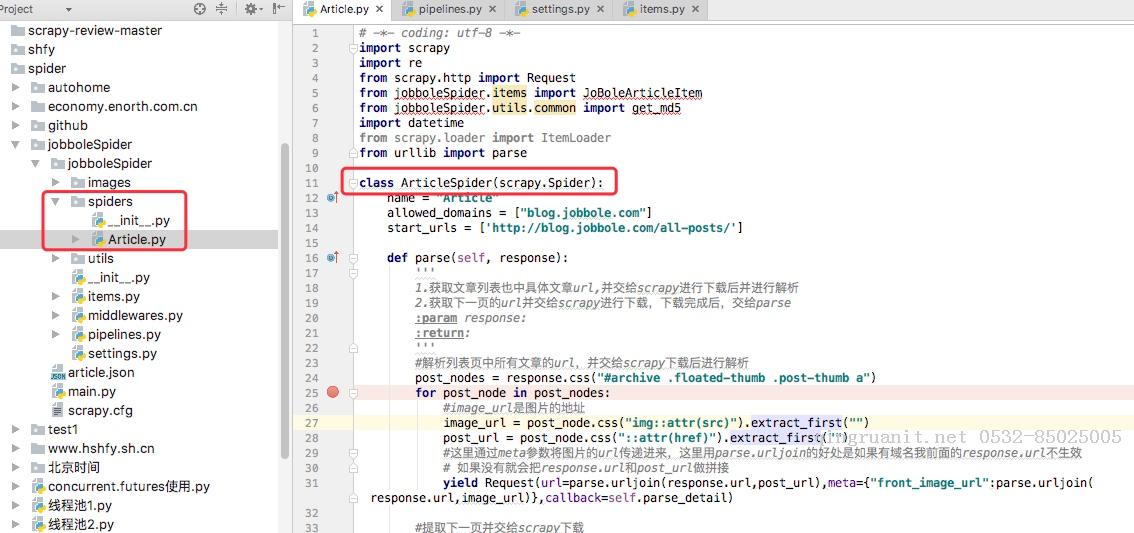
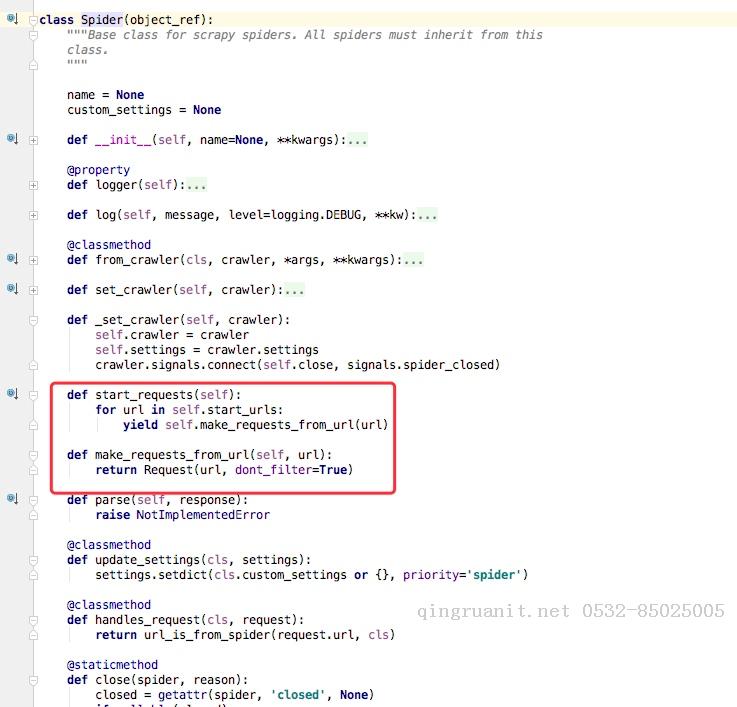
通过上述代码我们可以看到在父类里这里实现了start_requests方法,通过make_requests_from_url做了Request请求
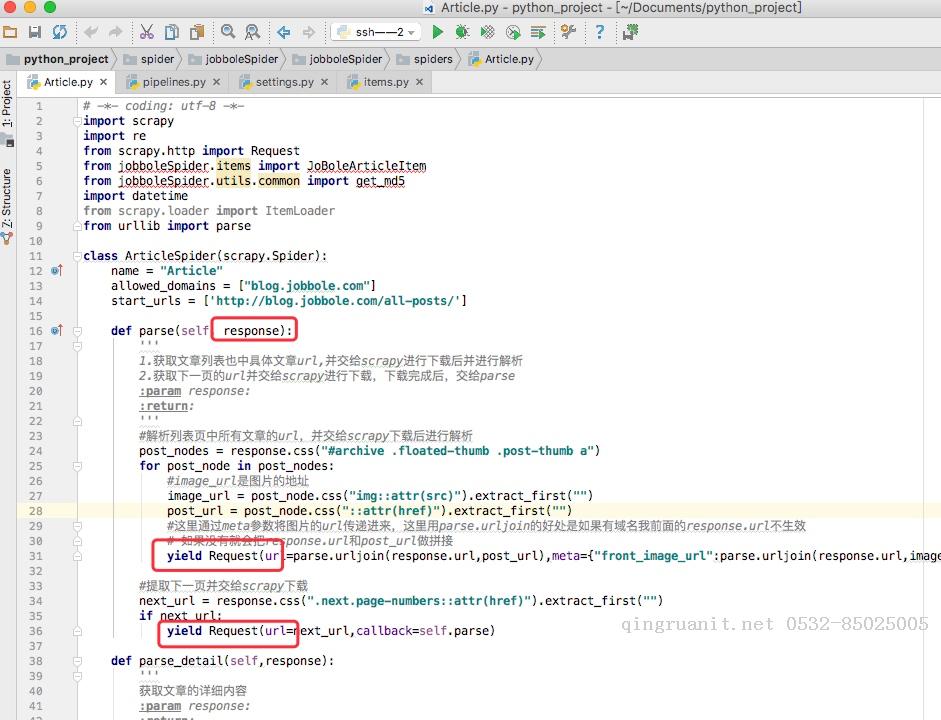
如下图所示的一个例子,parse回调函数中的response就是父类列start_requests方法调用make_requests_from_url返回的结果,并且在parse回调函数中我们可以继续返回Request,如下属代码中yield Request()并设置回调函数。
spider内的一些常用属性
我们所有自己写的爬虫都是继承与spider.Spider这个类
name
定义爬虫名字,我们通过命令启动的时候用的就是这个名字,这个名字必须是唯一的
allowed_domains
包含了spider允许爬取的域名列表。当offsiteMiddleware启用时,域名不在列表中URL不会被访问
所以在爬虫文件中,每次生成Request请求时都会进行和这里的域名进行判断
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式