这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解
该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider/tree/master/jobboleSpider
注:这个文章并不会对详细的用法进行讲解,是为了让对scrapy各个功能有个了解,建立整体的印象。
在学习Scrapy框架之前,我们先通过一个实际的爬虫例子来理解,后面我们会对每个功能进行详细的理解。
这里的例子是爬取http://blog.jobbole.com/all-posts/ 伯乐在线的全部文章数据
分析要爬去的目标站信息
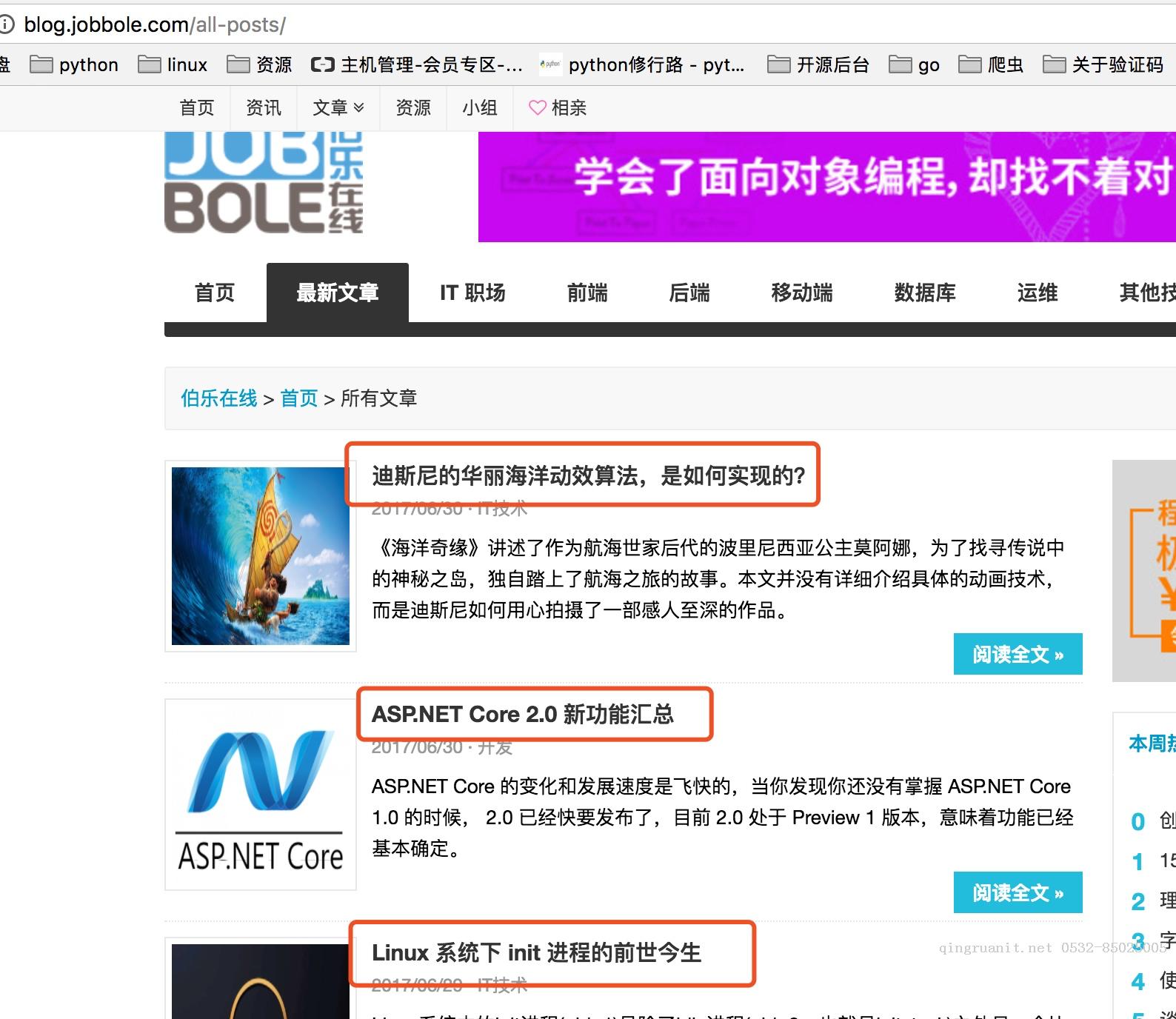
先看如下图,首先我们要获取下图中所有文章的连接,然后是进入每个文章连接爬取每个文章的详细内容。
每个文章中需要爬取文章标题,发表日期,以及标签,赞赏收藏,评论数,文章内容。
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式