Python开发简单爬虫(一)
一 、简单爬虫架构:
爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况
URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器”
网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器”
网页解析器:解析网页可解析出 ①有价值的数据 ②另一方面,每个网页都包含有指向其他网页的URL,解析出来后可补充进“URL管理器”,不断循环。
二、简单爬虫架构的动态运行流程
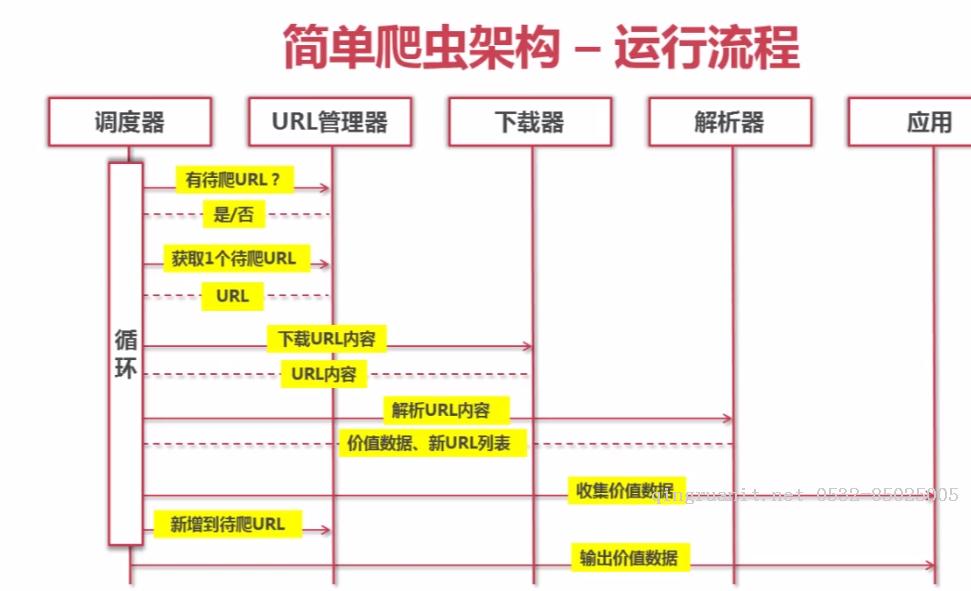
三、爬虫URL管理
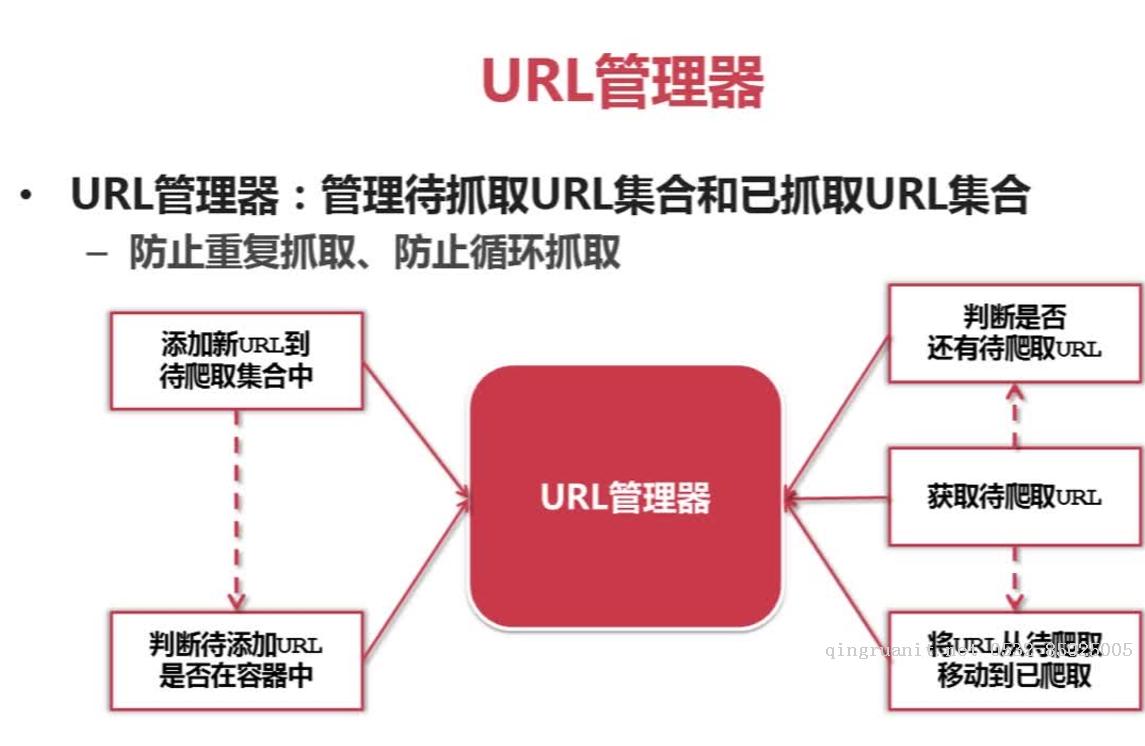
URL管理器:管理待抓取URL集合和已抓取URL集合 防止重复抓取。
url: 添加新url到爬取集合中, 判断待添加url是否在容器中, 判断是否还有待爬取的url, 获取待爬取url, 将url从待爬移动到已爬
四、爬虫URL管理器的实现方式
URL管理器的三种实现方式:内存、关系数据库、缓存数据库
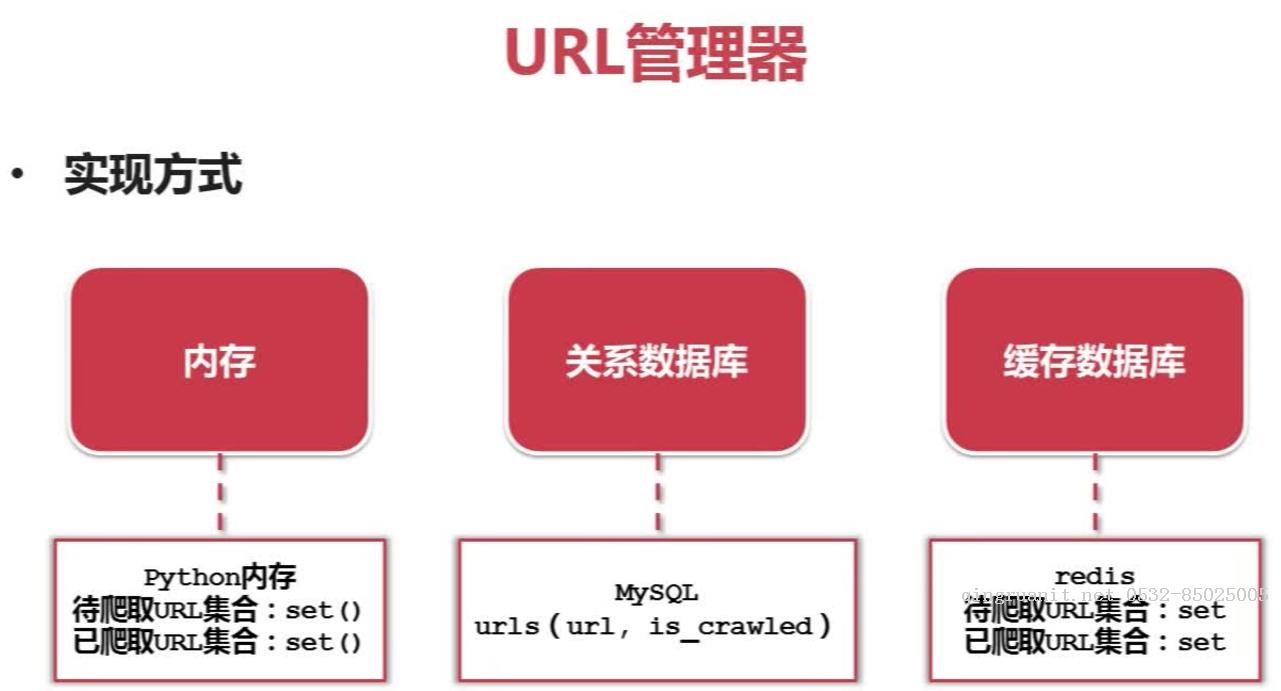
存放在内存中是利用set()集合,可以去除重复元素,利用MySQL里的is_crawled参数是用来标记已爬取还是未爬取,redis数据库同样利用set集合。
五、爬虫网页下载器
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式