一、为什么要混淆
为了避免apk在发布后被用户通过反编译拿到源代码和资源文件,然后修改资源和代码之后就变成一个新的apk。而经过混淆后的APK,即使被反编译,也难以阅读,注意混淆不是让apk不能阅读,而是加大阅读的难度,为了避免劳动成果被窃取,也避免出现安全漏洞和隐患,所以在apk发布之前一定要进行混淆。
二、混淆的原理
Java是一种跨平台、解释型语言,Java源代码编译成的class文件中有大量包含语义的变量名、方法名的信息,很容易被反编译为Java源代码。为了防止这种现象,我们可以对Java字节码进行混淆。混淆不仅能将代码中的类名、字段、方法名变为无意义的名称,保护代码,也由于移除无用的类、方法,并使用简短名称对类、字段、方法进行重命名缩小了程序的大小。
ProGuard由shrink、optimize、obfuscate和preverify四个步骤组成,每个步骤都是可选的,需要哪些步骤都可以在脚本中配置。参见ProGuard官方介绍。
压缩(Shrink):默认开启,侦测并移除代码中无用的类、字段、方法和特性,减少应用体积,并且会在优化动作执行之后再次执行(因为优化后可能会再次暴露一些未使用的类和成员)。
-dontshrink 关闭混淆
优化(Optimize):默认开启,分析和优化字节码,让应用运行的更快。
-dontoptimize 关闭优化,默认混淆配置文件开始
-optimizationpasses n 表示proguard对代码进行迭代优化的次数,Android一般为5
混淆(Obfuscate):默认开启,使用a、b、c、d这样简短而无意义的名称,对类、字段和方法进行重命名,增大反编译难度。
-dontobfuscate 关闭混淆
上面三个步骤使代码大小更小、更高效,也更难被逆向工程。
预检(Preverify):在java平台上对处理后的代码进行预检。
混淆流程图:
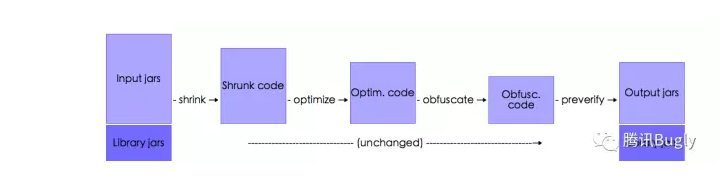
Proguard读入input jars(or wars,zip or directories),经过四个步骤生成处理之后的jars(or wars,ears,zips or directories),Optimization步骤可选择多次进行。
为了确定哪些代码应该被保留,哪些代码应该被移除或混淆,需要确定一个或多个Entry Point。Entry Point经常是带有main methods,applets,midlets的classes,它们在混淆过程中会被保留。
Proguard的几个步骤如何处理Entry Points。
(1).在压缩阶段,Proguard从上述E
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式