简介
在大型项目中,我们会遇到分表分库的情景。
分库,将不同模块对应的表拆分到对应的数据库下,其实伴随着公司内分布式系统的出现,这个过程也是自然而然就发生了,对应商品模块和用户模块,我们会建立商品服务和用户服务,各个服务访问各自的数据库,系统间的交互,通过远程调用实现,而不是直接访问其数据库。
但是随着业务的进一步发展,数据表也会出现瓶颈,比如数据表的记录已经超过了千万级,到了这个量级,速度也会慢下来。所以接下来就是分表。 比如用户表,我们会分user_1,user_2,user_3,....,我们会按照用户的Id取模的方式来定位表,假如用户表有3个,则Id是5的用户信息会落在第二张表。 分表的方式多种多样,比如商品表就适合按照日期来分表,一个月一张。 (分表还有一种是将不同的字段,分配到不同的表中)
对比
目前我所知道的分表的方式,大概有以下几种
1.自己手动控制,来决定操作那张表,比如要查询Id为5的用户信息,则会先5%(表的个数)=N 然后通过字符串拼接user_+"N"的方式得到表名,然后再访问数据库。
2. sql解析替换,比如要查询Id为5的用户信息,sql为select * from user,这里user表其实在数据库中不存在,是一个逻辑表,在调用的更底层,会解析这个sql语句,找出表名,然后根据分表规则,替换成具体的表名。 这种方式比上面的侵入性要底。
3. 代理方式,其实和上面的类似,只是具体替换工作是代理服务器做的,在连接数据库服务器的时候,我们连接的是代理,代理再连接数据库,我们执行一个sql语句,会先发送到代理服务器,代理服务器根据预先指定的分库分表规则,路由到具体的数据库。 对于我们系统来说,就是零侵入。
4. 数据库服务器本身的支持,比如sql server本本身就支持分表。
数据分表看似简单, 其实也非常困难,比如:
在应对Join查询上,我们不能再像原来那么操作。
在未使用分表规则时的查询,比如,用户表是按照Id取模分表的,但是如果有一个查询是select * from user where loginid='XX' , 那就相当于要并行查询多张表。
在面对批量插入的时候。
等等。 当想要把分表做的更通用,更透明时,都会面对这个问题。
我的解决方案
我的想法和上面第一种比较类似,我想做的更通用一些,但是表名是始终绕不过去的,后来索性换了一种思路,既然这样做如此麻烦,那表名就不替换了,替换库,这就是我标题里说的,用分库的思想来分表,同时还得到另外的一个好处,就是当数据库服务器IO遇到瓶颈的时候,可以将这些数据库中一部分迁移到其他机器上。
比如 用户表(user)需要分成3个,那我就新建3个数据库,每个数据库中各有一张表(user),当我执行select * from user where id=5 的时候,我会根据规则,切换数据库连接,这个sql里面的user表,在对应数据库里是真实存在的。 这些数据库可以在同一台机器上,当服务器遇到压力时,可以将这3个数据库分布到3台机器上去,比起迁表,迁库更容易。
有了这个思路,接下来就是如何尽可能的低浸入,这里我使用.net的Attribute(当然,也可以搞成配置文件方式),通过给方法打标签来提供一些信息,最后就是如何解析这些标签,我这里使用AOP, 当然完全的零侵入是不可能的,但是也只是需要你在访问数据库的方法中,多一行代码,就是获取数据库连接的。
我们先看数据访问层
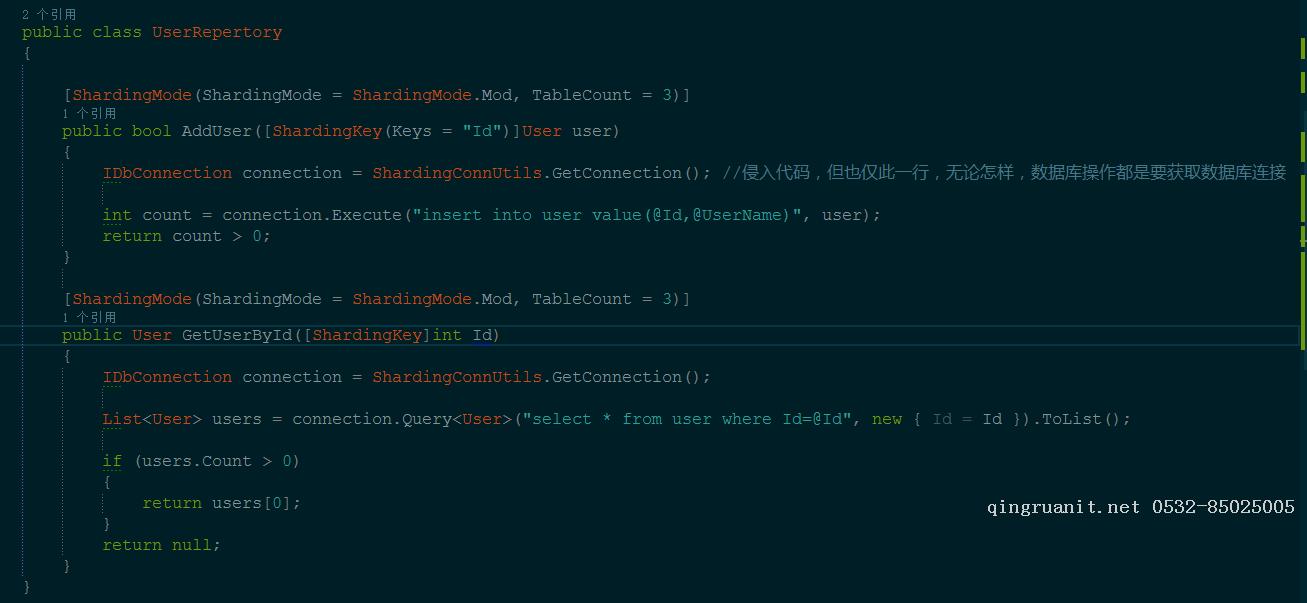
这里数据访问我用的是dapper,对于需要分
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式