本篇深入了解查询优化和服务器的内部机制,了解MySql如何执行特定查询,从中也可以知道如何更改查询执行计划,当我们深入理解MySql如何真正地执行查询,明白高效和低效的真正含义,在实际应用中就能扬长避短。
声明:本人使用的数据库版本为MySql 5.1
一、基本原则:优化数据访问
查询性能低下的最基本原因就是访问了太多数据,一些查询要不可避免地筛选大量的数据,大部分性能欠佳的查询都可以用减少数据访问的方式进行优化。
1、首先分析应用程序是否正在获取超过需要的数据,这通常表现在获取了过多的行或列。一些查询先向服务器请求不需要的数据,再丢掉他们,这个让服务器造成了额外的负担,增加了网络开销,消耗了内存和CPU资源。
> 如果前台只需要显示15条数据,而你的查询结果集返回了100条,则要想想是否真有必要这样干了,最好使用LIMIT来限制查询的条数。
> 尽量避免使用SELECT * , 也许你并不需要所有的列,但获取所有的列将会造成覆盖索引这样的优化手段失效,也会增加磁盘I/O、内存和CPU的开销等,所以基于这种情况,尽量使用SELECT t.id, t.name ... 这种查询具体字段的SQL。
但是,SELECT * 这种稍显浪费的方式可以简化开发,增加代码的复用性(比如以后扩展了字段,就不用再改sql代码了)。
如果系统使用了持久化框架,而我们只查询了某一些字段出来,然后再直接去更新这个持久化对象时,那些未查询出来的字段就会被设置为NULL,导致数据丢失。所以,如果只查询一部分字段,要避免去更新持久化对象(亲身经历)。
在程序中,还是倡导使用SELECT t.id, t.name ... 这种形式,能更好地利用索引;如果只是显示数据,那就按需查询部分字段即可,这样能更充分利用覆盖索引;如果需要更新数据,则必须查询出所有字段。
2、其次看是否检查了过多的数据,一般从查询的执行时间、检查的行数、返回的行数来看,但这些不可作为绝对的标准。
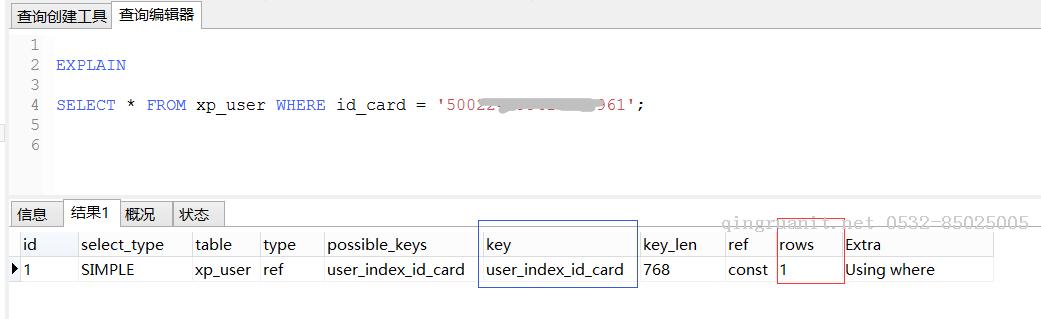
> 看下面的这个执行计划:
第一幅图中:key表明使用了id_card索引;rows=1,表明只检查了一行数据,所以其速度是很快的。
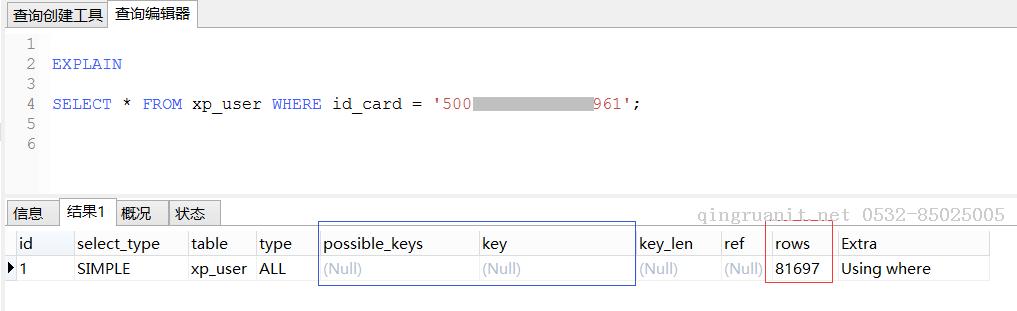
第二幅图中:删除了索引后的执行计划,没有使用索引,检查的行数是81697,而我们只需要一行数据;而如果数据量不断增加,再与其它表关联查询的话,其性能可想而知是有多低效。
所以,查看是否检查了过多的行,使用一些优化手段如利用好索引或者重构查询尽量去减少检查的行数。
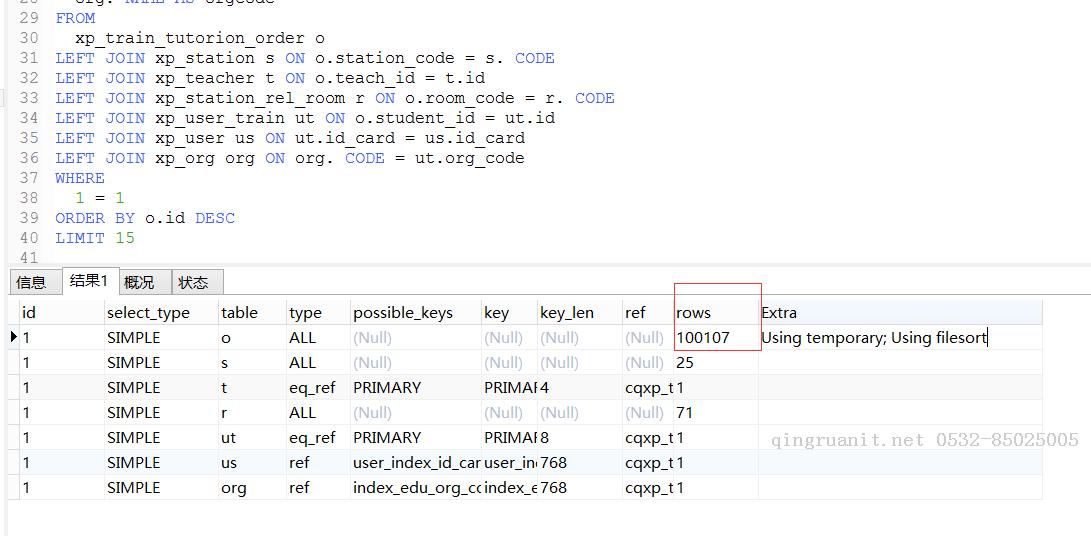
> 再看下面这个执行计划:
这个查询联接了多张表,仅第一张表就检查了10W行(而我们只需要15行),然后再与其它表进行联接,再排序,效率自然低下了。而其它检查出只有一行的表,可看出其使用了索引列进行联接,可见使用好索引的高效。
看第二幅图:使用了一个子查询以减少检查的行数,加上id列本身是排好序的,所以Extra列可以看到没有使用临时表进行文件排序了,在第一幅图中,使用临时表排序(using temporyary,using filesort)是很耗时的。
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式