
在K-Means聚类算法原理中,我们讲到了K-Means和Mini Batch K-Means的聚类原理。这里我们再来看看另外一种常见的聚类算法BIRCH。BIRCH算法比较适合于数据量大,类别数K也比较多的情况。它运行速度很快,只需要单遍扫描数据集就能进行聚类,当然需要用到一些技巧,下面我们就对BIRCH算法做一个总结。
1. BIRCH概述
BIRCH的全称是利用层次方法的平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies),名字实在是太长了,不过没关系,其实只要明白它是用层次方法来聚类和规约数据就可以了。刚才提到了,BIRCH只需要单遍扫描数据集就能进行聚类,那它是怎么做到的呢?
BIRCH算法利用了一个树结构来帮助我们快速的聚类,这个数结构类似于平衡B+树,一般将它称之为聚类特征树(Clustering Feature Tree,简称CF Tree)。这颗树的每一个节点是由若干个聚类特征(Clustering Feature,简称CF)组成。从下图我们可以看看聚类特征树是什么样子的:每个节点包括叶子节点都有若干个CF,而内部节点的CF有指向孩子节点的指针,所有的叶子节点用一个双向链表链接起来。
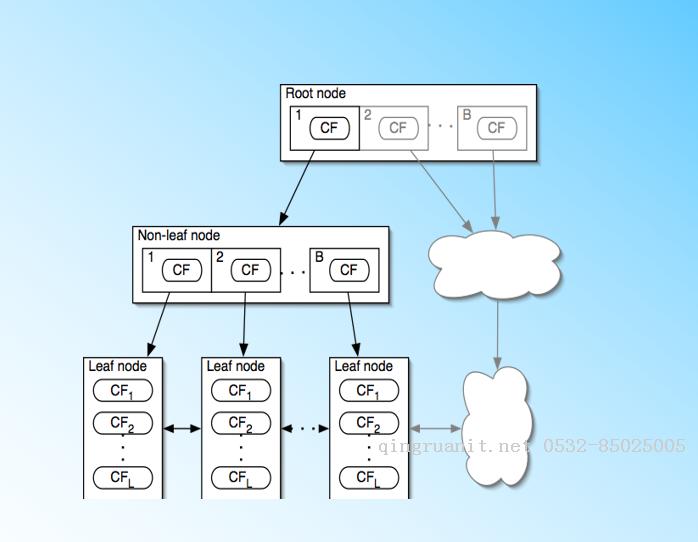
有了聚类特征树的概念,我们再对聚类特征树和其中节点的聚类特征CF做进一步的讲解。
2. 聚类特征CF与聚类特征树CF Tree
在聚类特征树中,一个聚类特征CF是这样定义的:每一个CF是一个三元组,可以用(N,LS,SS)表示。其中N代表了这个CF中拥有的样本
