
本文旨在提供最基本的,可以用于在生产环境进行Hadoop、HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用。
一、基础环境
在Linux上安装Hadoop之前,需要先安装两个程序:
1.1 安装说明
1. JDK 1.6或更高版本(本文所提到的安装的是jdk1.7);
2. SSH(安全外壳协议),推荐安装OpenSSH。
下面简述一下安装这两个程序的原因:
1. Hadoop是用Java开发的,Hadoop的编译及MapReduce的运行都需要使用JDK。
2. Hadoop需要通过SSH来启动salve列表中各台主机的守护进程,因此SSH也是必须安装的,即使是安装伪分布式版本(因为Hadoop并没有区分集群式和伪分布式)。对于伪分布式,Hadoop会采用与集群相同的处理方式,即依次序启动文件conf/slaves中记载的主机上的进程,只不过伪分布式中salve为localhost(即为自身),所以对于伪分布式Hadoop,SSH一样是必须的。
1.1 JDK的安装与配置
1、上传压缩包
我这里使用的是WinScp工具 上传jdk-7u76-linux-x64.tar.gz压缩包
2、解压压缩包
tar -zxvf jdk-7u76-linux-x64.tar.gz
3、将解压的目录移动到/usr/local目录下
mv /lutong/jdk1.7.0_76/ /usr/local/

4、配置环境变量
vim /etc/profile
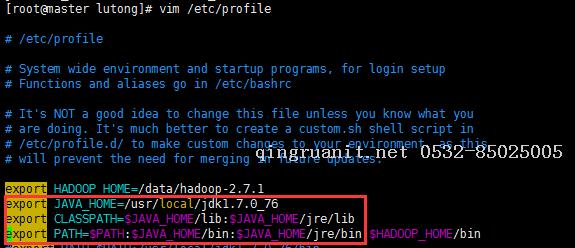
5、重新加载/etc/profile,使配置生效
source /etc/profile
6、查看配置是否生效
echo $PATH
java -version

出现如上信息表示已经配置好了。
二、Host配置
由于我搭建Hadoop集群包含三台机器,所以需要修改调整各台机器的hosts文件配置,进入/etc/hosts,配置主机名和ip的映射,命令如下:
vim /etc/hosts
如果没有足够的权限,可以切换用户为root。
三台机器的内容统一增加以下host配置:
可以通过hostname来修改服务器名称为master、slave1、slave2
hostname master

三、Hadoop的安装与配置
3.1 创建文件目录
为了便于管理,给Master的hdfs的NameNode、DataNode及临时文件,在用户目录下创建目录:
/data/hdfs/name
/data/hdfs/data
/data/hdfs/tmp
然后将这些目录通过scp命
