
最近上线的项目中数据库数据已经临近饱和,最大的一张表数据已经接近3000W,百万数据的表也有几张,项目要求读数据(select)时间不能超过0.05秒,但实际情况已经不符合要求,explain建立索引,使用redis,ehcache缓存技术也已经满足不了要求,所以开始使用读写分离技术,可能以后数据量上亿或者更多的时候,需要再去考虑分布式数据库的部署,但目前来看,读写分离+缓存+索引+表分区+sql优化+负载均衡是可以满足亿级数据量的查询工作的,现在就一起来看一下亲测可用的使用spring实现读写分离的步骤:
1. 背景
我们一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是说采用数据库集群的方案,
其中一个是主库,负责写入数据,我们称之为:写库;
其它都是从库,负责读取数据,我们称之为:读库;
那么,对我们的要求是:
1、读库和写库的数据一致;(这个是很重要的一个问题,处理业务逻辑要放在service层去处理,不要在dao或者mapper层面去处理)
2、写数据必须写到写库;
3、读数据必须到读库;
2. 方案
解决读写分离的方案有两种:应用层解决和中间件解决。
2.1. 应用层解决:
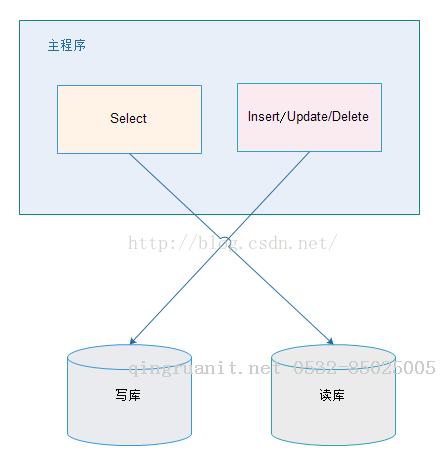
优点:
1、多数据源切换方便,由程序自动完成;
2、不需要引入中间件;
3、理论上支持任何数据库;
缺点:
1、由程序员完成,运维参与不到;
2、不能做到动态增加数据源;
