
1.概述
目前,随着大数据的浪潮,Kafka 被越来越多的企业所认可,如今的Kafka已发展到0.10.x,其优秀的特性也带给我们解决实际业务的方案。对于数据分流来说,既可以分流到离线存储平台(HDFS),离线计算平台(Hive仓库),也可以分流实时流水计算(Storm,Spark)等,同样也可以分流到海量数据查询(HBase),或是及时查询(ElasticSearch)。而今天笔者给大家分享的就是Kafka 分流数据到 ElasticSearch。
2.内容
我们知道,ElasticSearch是有其自己的套件的,简称ELK,即ElasticSearch,Logstash以及Kibana。ElasticSearch负责存储,Logstash负责收集数据来源,Kibana负责可视化数据,分工明确。想要分流Kafka中的消息数据,可以使用Logstash的插件直接消费,但是需要我们编写复杂的过滤条件,和特殊的映射处理,比如系统保留的`_uid`字段等需要我们额外的转化。今天我们使用另外一种方式来处理数据,使用Kafka的消费API和ES的存储API来处理分流数据。通过编写Kafka消费者,消费对应的业务数据,将消费的数据通过ES存储API,通过创建对应的索引的,存储到ES中。其流程如下图所示:
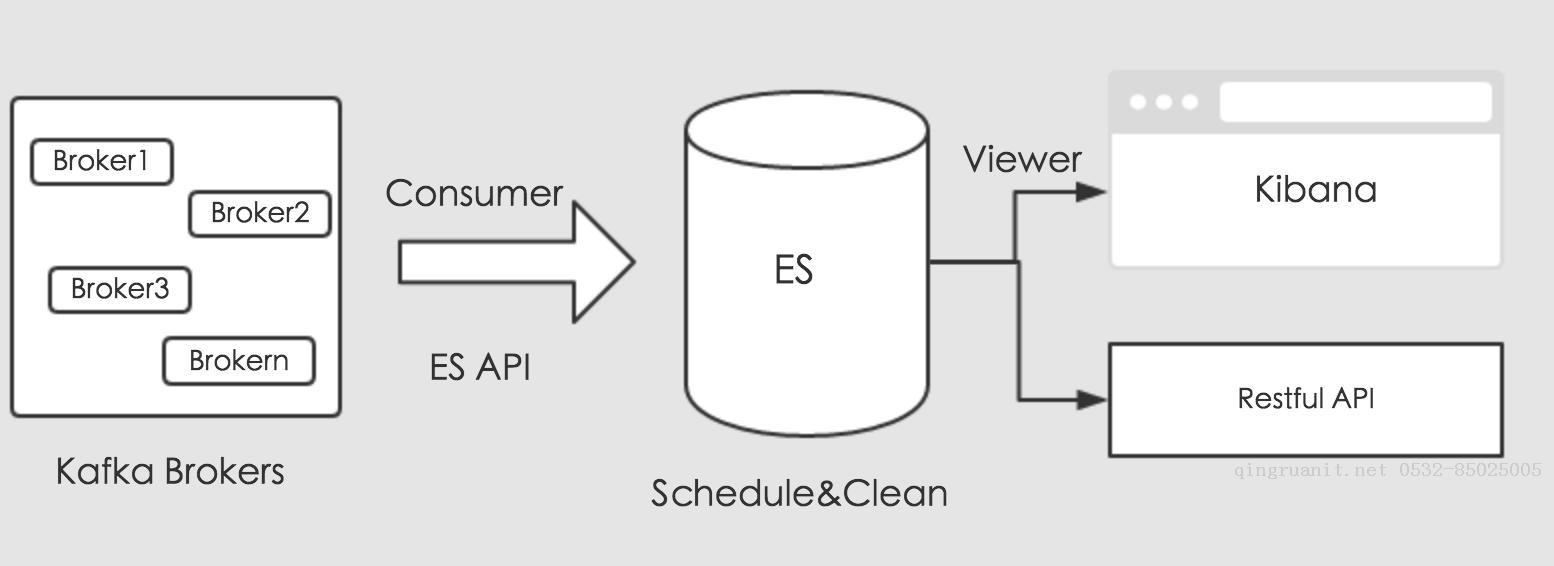
上图可知,消费收集的数据,通过ES提供的存储接口进行存储。存储的数据,这里我们可以规划,做定时调度。最后,我们可以通过Kibana来可视化ES中的数据,对外提供业务调用接口,进行数据共享。
3.实现
下面,我们开始进行实现细节处理,这里给大家提供实现的核心代码部分,实现代码如下所示:
3.1 定义ES格式
我们以插件的形式进行消费,从Kafka到ES的数据流向,只需要定义插件格式,如下所示:

{ "job": { "content": { "reader": { "name": "kafka", "parameter": {
