一、Lucene基本介绍:
基本信息:Lucene 是 Apache 软件基金会的一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
文件结构:自上而下树形展开,一对多。
索引Index:相当于库或者表。
段Segment:相当于分库或者分表。
文档Document:相当一条数据 ,如小说吞噬星空
域Field:一片文档可以分为多个域,相当于字段,如:小说作者,标题,内容。。。
词元Term:一个域又可以分为多个词元,词元是做引搜索的最小单位,标准分词下得词元是一个个单词和汉字。
正向信息:
索引->段->文档->域->词
反向信息:
词->文档。
二、Lucene全文检索:
1、数据分类:
结构化数据:数据库,固定长度和格式的数据。
半结构化数据:如xml,html,等..。
非结构化数据:长度和格式都不固定的数据,如文本...
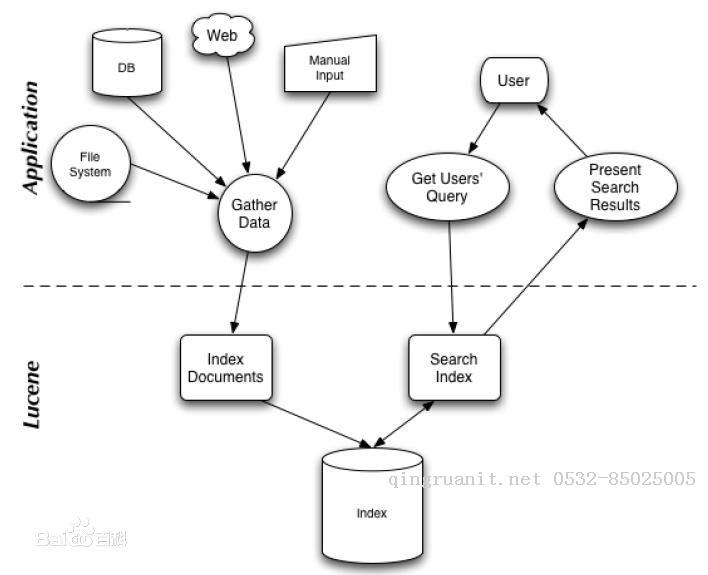
2、检索过程:Luncene检索过程可以分为两个部分,一个部分是上图左侧结构化,半结构化,非结构化数据的索引建立过程,另一部分是右侧索引查询过程。
索引过程:
有一系列被索引文件
被索引文件经过语法分析和语言处理形成一系列词(Term)。
经过索引创建形成词典和反向索引表。
通过索引存储将索引写入硬盘/内存。
搜索过程:
用户输入查询关键字。
对查询语句经过语法分析和语言分析得到一系列词(Term)。
通过语法分析得到一个查询树。
通过索引存储将索引读入到内存。
利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
将搜索到的结果文档对查询的相关性进行排序。
返回查询结果给用户。