
考虑到学习知识的顺序及效率问题,所以后续的几种聚类方法不再详细讲解原理,也不再写python实现的源代码,只介绍下算法的基本思路,使大家对每种算法有个直观的印象,从而可以更好的理解函数中参数的意义及作用,而重点是放在如何使用及使用的场景。
(题外话: 今天看到一篇博文:刚接触机器学习这一个月我都做了什么? 里面对机器学习阶段的划分很不错,就目前而言我们只要做到前两阶段即可)
因为前两篇博客已经介绍了两种算法,所以这里的算法编号从3开始。
3.Mean-shift
1)概述
Mean-shift(即:均值迁移)的基本思想:在数据集中选定一个点,然后以这个点为圆心,r为半径,画一个圆(二维下是圆),求出这个点到所有点的向量的平均值,而圆心与向量均值的和为新的圆心,然后迭代此过程,直到满足一点的条件结束。(Fukunage在1975年提出)
后来Yizong Cheng 在此基础上加入了 核函数 和 权重系数 ,使得Mean-shift 算法开始流行起来。目前它在聚类、图像平滑、分割、跟踪等方面有着广泛的应用。
2)图解过程
为了方便大家理解,借用下几张图来说明Mean-shift的基本过程。
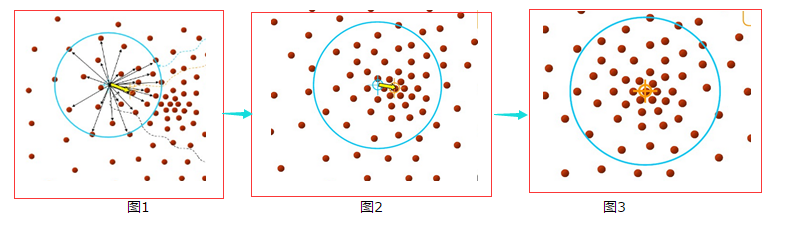
由上图可以很容易看到,Mean-shift 算法的核心思想就是不断的寻找新的圆心坐标,直到密度最大的区域。
3)Mean-shift 算法函数
a)核心函数:sklearn.cluster.MeanShift(核函数:RBF核函数)
由上图可知,圆心(或种子)的确定和半径(或带宽)的选择,是影响算法效率的两个主要因素。所以在sklearn.cluster.MeanShift中重点说明了这两个参数的设定问题。
b)主要参数
bandwidth :半径(或带宽),float型。如果没有给出,则使用sklearn.cluster.estimate_bandwidth计算出半径(带宽).(可选)
seeds :圆心(或种子),数组类型,即初始化的圆心。(可选)
