
前段时间业务反映某类服务器上更新了 bash 之后,ssh 连上去偶发登陆失败,客户端吐出错误信息如下所示:
图 - 0
该版本 bash 为部门这边所定制,但是实现上与原生版并没有不同,那么这些错误从哪里来?
是 bash 的锅吗
从上面的错误信息可以猜测,异常是 bash 在启动过程中分配内存失败所导致,看起来像是某些情况下该进程错误地进行了大量内存分配,最后导致内存不足,要确认这个事情比较简单,动态内存分配到系统调用这一层上主要就两种方式: brk() 和 mmap(), 所以只要统计一下这两者的调用就可以大概估算出是否有大内存分配了。
bash 是由 sshd 启动的,于是 strace 跟踪了一下 sshd 进程,结果发现异常发生时,bash 分配的内存非常地少,少到有时甚至只有几十字节也会失败,几乎可以断定 bash 在内存使用上没有异常,但在这期间发现一个诡异的现象,Bash 一直只用 brk 在分配小内存,brk() 失败后就直接退出了,一般程序使用的 libc 中的 malloc (或其它类似的 malloc) 会结合 brk 和 mmap 一起使用【0】,不至于 brk 一失败就分配不到内存,顺手查看了下 bash 的源码,发现它确实基于 brk 做了自己的内存管理,并没有使用 malloc 或 mmap。
但那并不是重点,重点是即使是只使用 brk,也不至于只能分配几十字节的内存。
进程的内存布局
进程的内存布局在结构上是有规律的,具体来说对于 linux 系统上的进程,其内存空间一般可以粗略地分为以下几大段【1】,从高内存到低内存排列:
1、内核态内存空间,其大小一般比较固定(可以编译时调整),但 32 位系统和 64 位系统的值不一样。
2、用户态的堆栈,大小不固定,可以用 ulimit -s 进行调整,默认一般为 8M,从高地址向低地址增长。
3、mmap 区域,进程茫茫内存空间里的主要部分,既可以从高地址到低地址延伸(所谓 flexible layout),也可以从低到高延伸(所谓 legacy layout),看进程具体情况【2】【3】。
4、brk 区域,紧邻数据段(甚至贴着),从低位向高位伸展,但它的大小主要取决于 mmap 如何增长,一般来说,即使是 32 位的进程以传统方式延伸,也有差不多 1 GB 的空间(准确地说是 TASK_SIZE/3 - 代码段数据段,参看 arch/x86/include/asm/processor.h 里宏 TASK_UNMAPPED_BASE 的定义)【4】
5、数据段,主要是进程里初始化和未初始化的全局数据总和,当然还有编译器生成一些辅助数据结构等等),大小取决于具体进程,其位置紧贴着代码段。
6、代码段,主要是进程的指令,包括用户代码和编译器生成的辅助代码,其大小取决于具体程序,但起始位置根据 32 位还是 64 位一般固定(-fPIC, -fPIE等除外【5】)。
以上各段(除了代码段数据段)其起始位置根据系统是否起用 randomize_va_space 一般稍有变化,各段之间因此可能有随机大小的间隔,千言万语不如一幅图:

图 - 1
所以现在的问题归结为:为什么目标进程的 brk 的区域突然那么小了,先检查一下 bash 的内存布局:
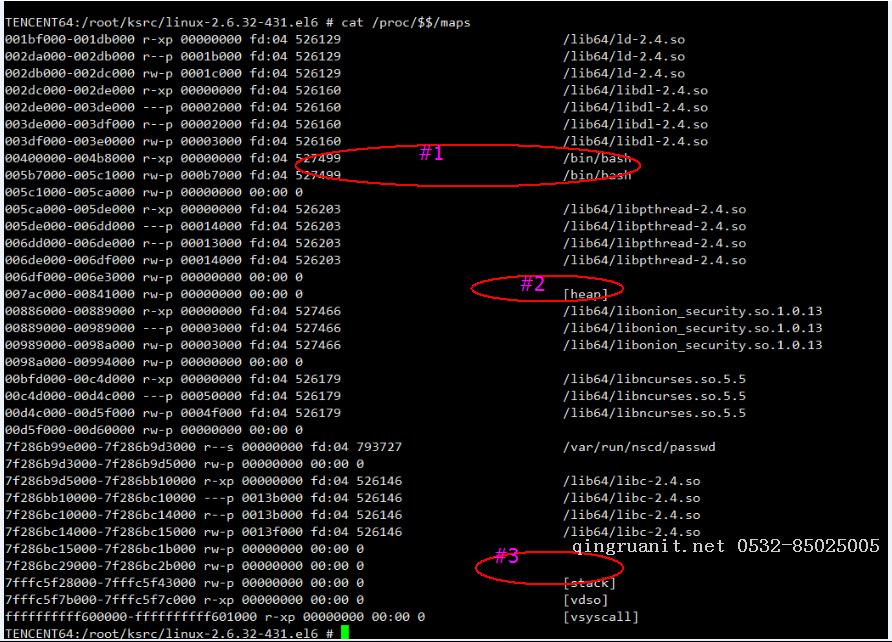
图 - 2
这个进程的内存布局和一般理解上有很大出入,从上往下是低内存到高内存:
网友评论
