如何不断扩充数据中心的数据规模,提升数据挖掘的价值,这是我们思考的问题,数据一方面来自于内部生产,一部分数据可以来自于互联网,互联网上的数据体量庞大,形态多样,之前blog里很多FMEer已经提出了方案,比如json,xml,正则表达式等等,但对于比较松散的HTML如何进行数据解析提取呢?我问了一下度娘,貌似没有FME下的文章,恰逢今天有时间,就写一点关于HTML提取的东东,算是自己做的笔记吧!
这次我要提取的范例数据来自国土资源局土地招拍挂系统,我要提取上面的交易结果以及地块信息,样式如下图:
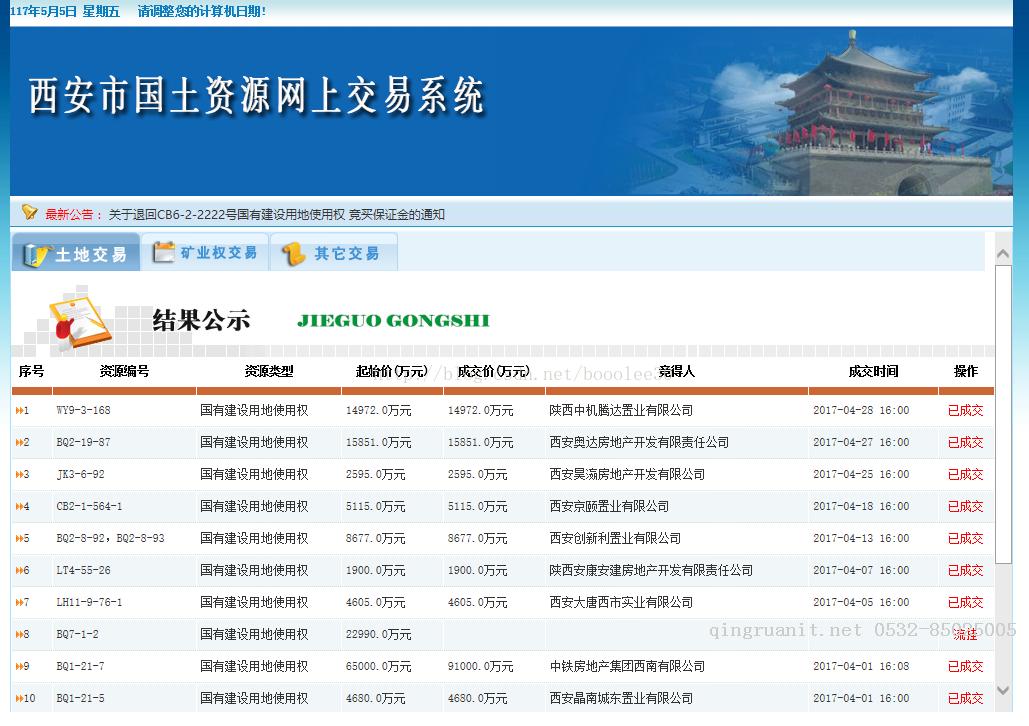
图1:交易结果列表

图2:地块信息
图3:转换工程
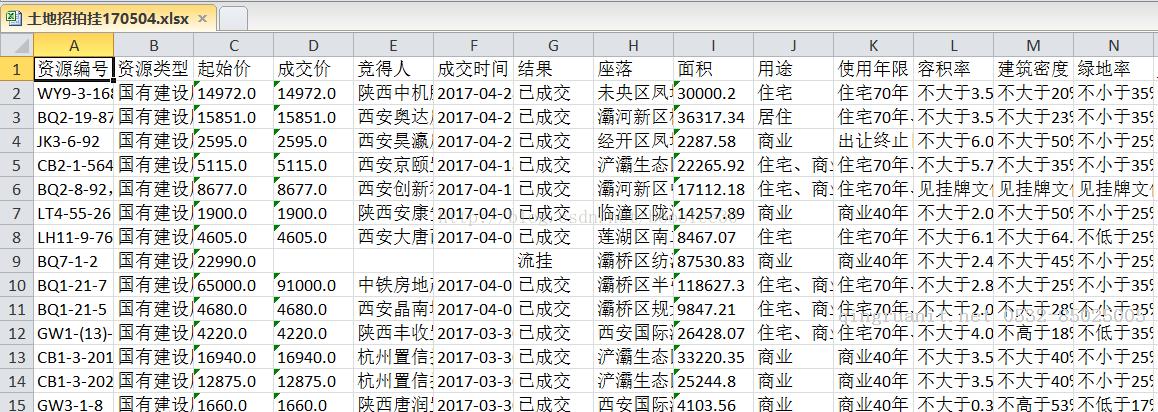
图4:提取后的数据
在这个转换工程里,用到了几个转换器,它们是:pythonCreator,HTTPCaller,HTMLExtractor、PythonCaller、StringSearcher、StringReplacer、AttributeExposer、AttributeRenamer、AttributeRemover
本文重点介绍一下HTMLExtractor,转换器的参数如下图:
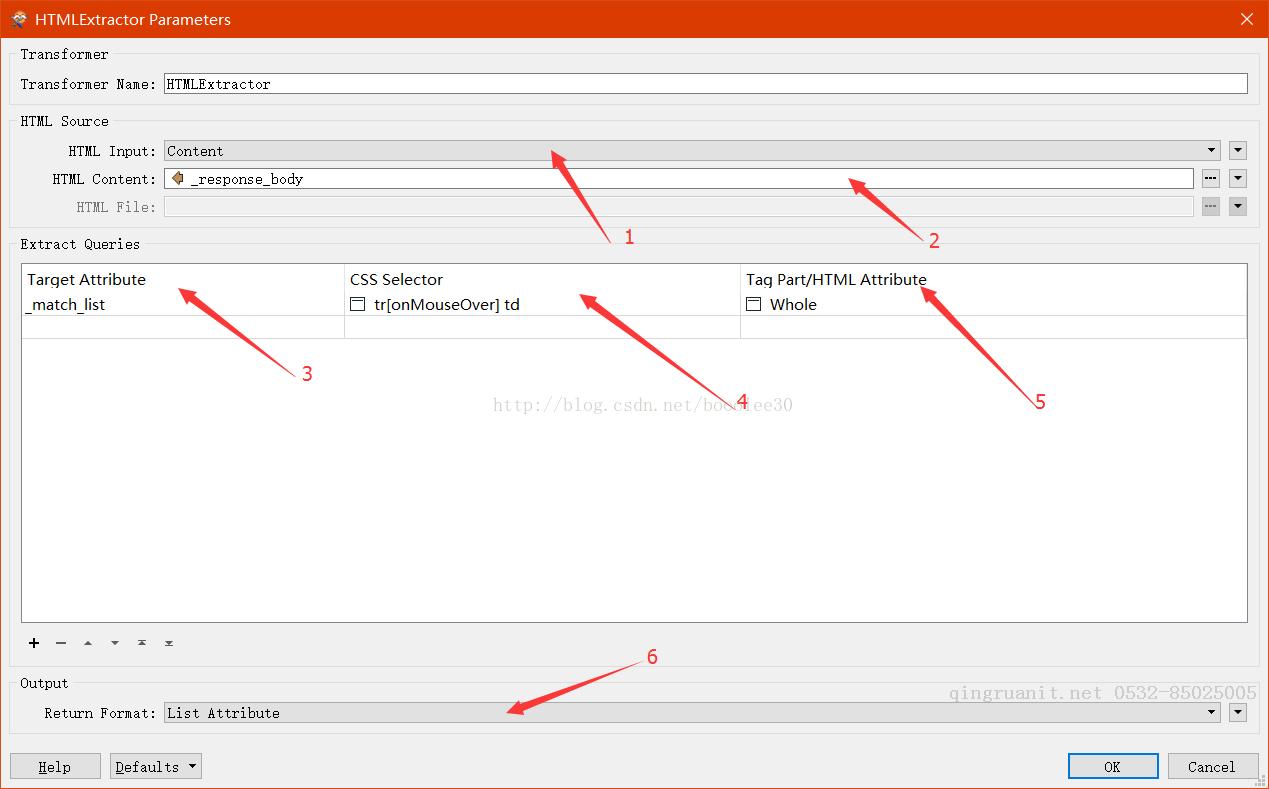
图5:HTMLExtractor参数
图上标注的参数依次是:
1、 HTML Input:HTML的内容来源,可以是content,表示来源于传入的属性、参数等,也可以是File,表示来源于一个已存在的HTML文件。
2、 HTML Content:本案例用的是content作为源,与HttpCaller连用,HTML存放于_response_body属性中。如果是File作为源,则需要设置HTML File为文件路径。
3、 Target Attribute:设置一个属性(列表)名称,这个属性名称将包含HTML解析的结果。
4、 CSS Selector:设置CSS选择器,类似正则表达式,但用起来更简单,特别适合解析HTML。
5、 Tag Part/HTML Attribute:可以设置为Value(匹配标签里的值)、Whole(匹配的标签和值)、或者输入匹配标签拥有的一个属性名称,比如<a>标记的href属性。
6、 Return Format:可以设置为List Attribute,则将所有匹配的内容作为一个list返回,如果为First Match,则仅返回第一个匹配的内容。
举个栗子,下面是我要匹配的交易结果HTML源文件:
<tr class="TR2" onMouseOver="this.className='TR3';" onMouseOut="this.className='TR2';">
<td height="31" align="left" class="TD1"><img src="images/arrow_yellow.gif">2</td>
<td class="TD1" align="left">BQ2-19-87</td>
<td class="TD1" align="left">国有建设用地使用权</td>
<td class="

IT网络文摘的软件学习笔记
学习就是力量
