
对于浏览器缓存,相信很多开发者对它真的是又爱又恨。一方面极大地提升了用户体验,而另一方面有时会因为读取了缓存而展示了“错误”的东西,而在开发过程中千方百计地想把缓存禁掉。那么浏览器缓存究竟是个什么样的神奇玩意呢?
什么是浏览器缓存:
简单来说,浏览器缓存就是把一个已经请求过的Web资源(如html页面,图片,js,数据等)拷贝一份副本储存在浏览器中。缓存会根据进来的请求保存输出内容的副本。当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。比较常见的就是浏览器会缓存访问过网站的网页,当再次访问这个URL地址的时候,如果网页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站明确标识资源已经更新,浏览器才会再次下载网页。至于浏览器和网站服务器是如何标识网站页面是否更新的机制,将在后面介绍。
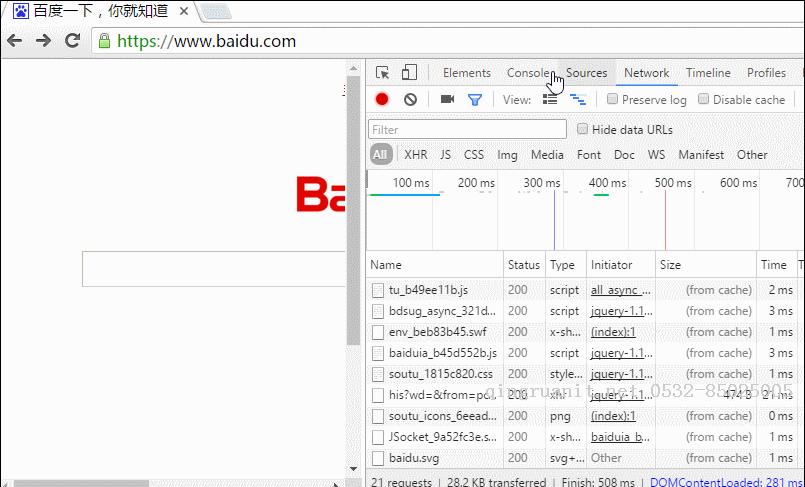
上图就是使用了缓存的栗子,在页面请求之后,web资源都被缓存了,在后面的重复请求中,可以看到许多资源都是直接从缓存中读取的(from cache),而不是重新去向服务器请求。
为什么使用缓存:
(1)减少网络带宽消耗
