摘要:
1.RDD的五大属性
1.1 partitions(分区)
1.2 partitioner(分区方法)
1.3 dependencies(依赖关系)
1.4 compute(获取分区迭代列表)
1.5 preferedLocations(优先分配节点列表)
2.RDD实现类举例
2.1 MapPartitionsRDD
2.2 ShuffledRDD
2.3 ReliableCheckpointRDD
3.RDD可以嵌套吗?
内容:
1.RDD的五大属性
1.1partitions(分区)
partitions : 分区属性: 每个RDD包括多个分区, 这既是RDD的数据单位, 也是计算粒度, 每个分区是由一个Task线程处理. 在RDD创建的时候可以指定分区的个数, 如果没有指定, 那么默认分区的个数是CPU的核数(standalone).
每一分区对应一个内存block, 由BlockManager分配.

子类可以通过调用下面的方法来获取分区列表,当处于检查点时,分区信息会被重写
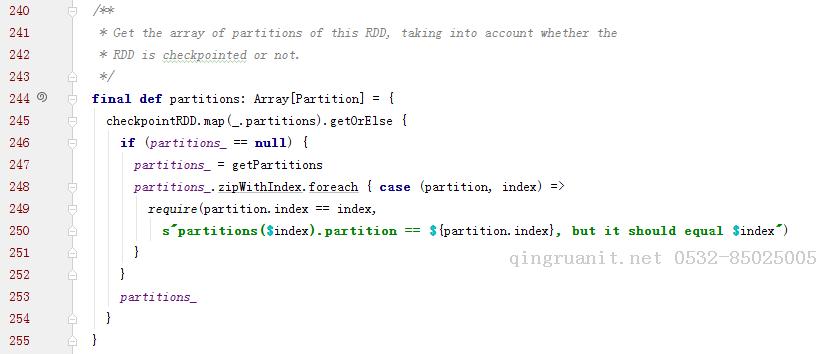
Partition实现:

partition 与 iterator 方法
RDD 的 iterator(split: Partition, context: TaskContext): Iterator[T] 方法用来获取 split 指定的 Partition 对应的数据的迭代器,有了这个迭代器就能一条一条取出数据来按 compute chain 来执行一个个transform 操作。iterator 的实现如下:

其先判断 RD
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式