上一节,我们介绍利用文本和知识库融合训练词向量的方法,如何更好的融合这些结构化知识呢?使得训练得到的词向量更具有泛化能力,能有效识别同义词反义词,又能学习到上下文信息还有不同级别的语义信息。
基于上述目标,我们尝试基于CBOW模型,将知识库中抽取的知识融合共同训练,提出LRWE模型。模型的结构图如下:
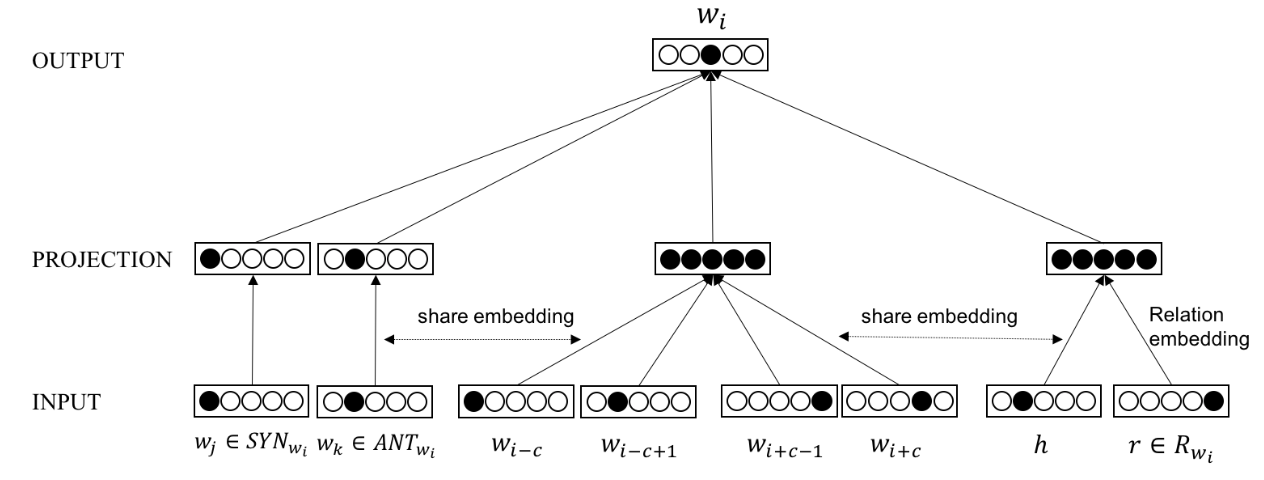
下面详细介绍该模型的思想和求解方法。
1. LWE模型
在Word2vec的CBOW模型中,通过上下文的词预测目标词,目标是让目标词在其给定上下文出现的概率最大,所以词向量训练的结果是与其上下文的词相关联的。然而 CBOW模型只考虑了词语的局部上下文信息,无法很好的表达同义词和反义词等信息。例如下面的几个case:

为了解决上述问题,本文将同义词和反义词等词汇信息以外部知识的形式,作为词向量训练中的监督数据,让训练得到的词向量能学习到同义、反义等词汇信息,从而能更好地区分同义词和反义词。
1.1 模型思想
记 ???? 的同义词和反义词集合为( ???? , ?????????? , ?????????? ),其中 SYN 表示同义词集合,ANT 表示反义词集合,我们的目标是已知目标词对应的同义词集合和反义词集合,预测目标词,使得目标词和它的同义词距离尽可能相近,与反义词距离尽可能远。
例如“The cat sat on the mat.”,已知sat有同义词seated,反义词stand,来预测目标词为sat。
该模型称为词汇信息模型,模型结构图如下:
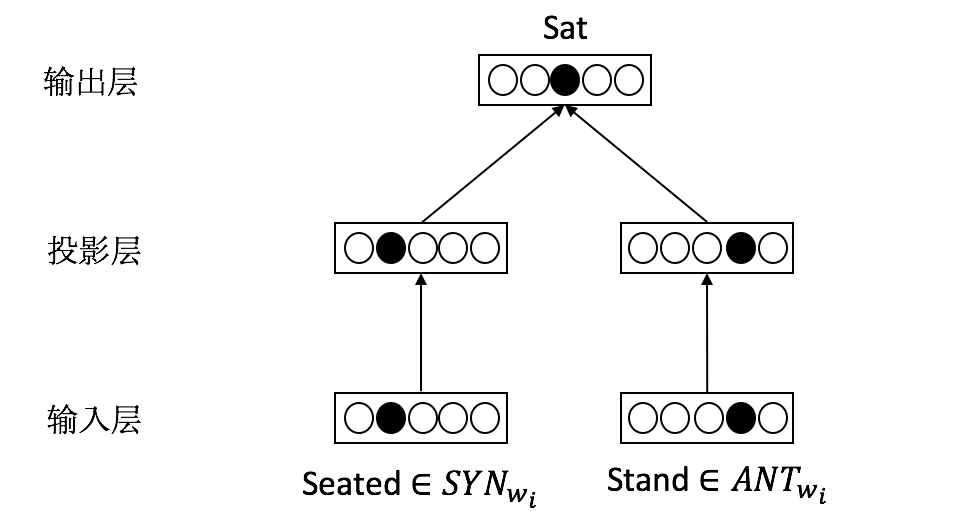
对于一个词语,我们根据它的同义词和反义词预测目标词,最大化词语和它的同义词同时出现的概率, 并降低词语和它反义词同时出现的概率。根据这个目标,定义以下的目标函数:


我们目标是在基于上下文的CBOW语言模型训练过程中,加入同义词反义词信息作为监督,使得训练所得词向量能学习到同义和反义知识。基于该想法,我们提出基于词汇信息的词向量模型(Lexical Information Word
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式