在前面的章节Client的加载中,Spark的DriverRunner已开始执行用户任务类(比如:org.apache.spark.examples.SparkPi),下面我们开始针对于用户任务类(或者任务代码)进行分析
一、整体预览
基于上篇图做了扩展,增加任务执行的相关交互
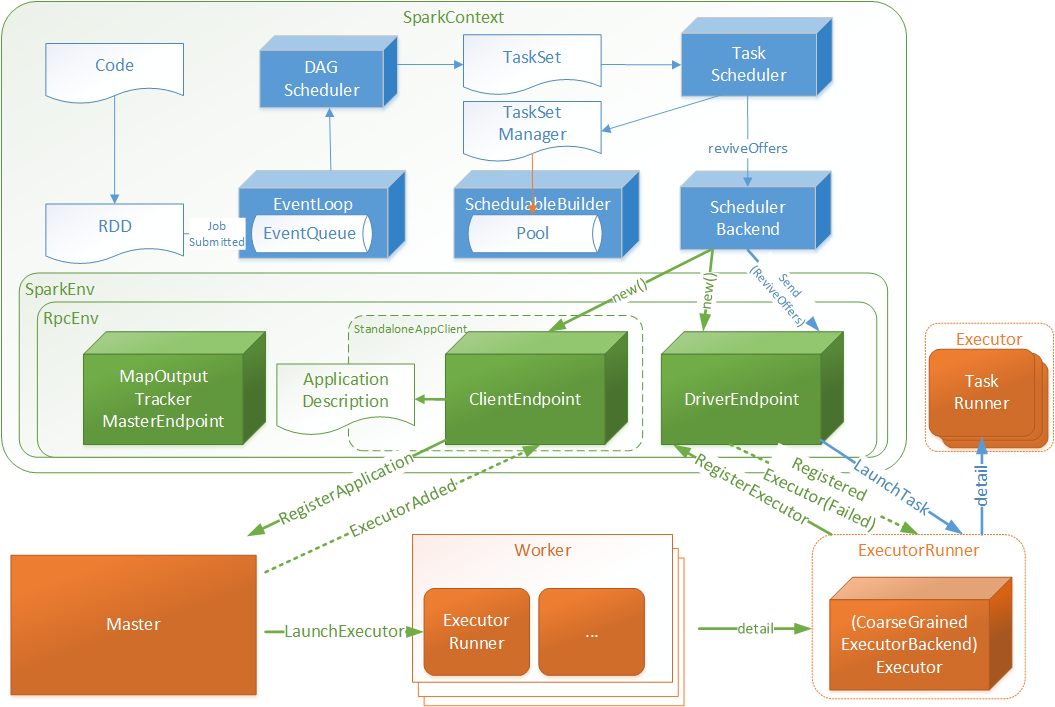
Code:指的用户编写的代码
RDD:弹性分布式数据集,用户编码根据SparkContext与RDD的api能够很好的将Code转化为RDD数据结构(下文将做转化细节介绍)
DAGScheduler:有向无环图调度器,将RDD封装为JobSubmitted对象存入EventLoop(实现类DAGSchedulerEventProcessLoop)队列中
EventLoop: 定时扫描未处理JobSubmitted对象,将JobSubmitted对象提交给DAGScheduler
DAGScheduler:针对于JobSubmitted进行处理,最终将RDD转化为执行TaskSet,并将TaskSet提交至TaskScheduler
TaskScheduler: 根据TaskSet创建TaskSetManager对象存入SchedulableBuilder的数据池(Pool)中,并调用DriverEndpoint唤起消费(ReviveOffers)操作
DriverEndpoint:接受ReviveOffers指令后将TaskSet中的Tasks根据相关规则均匀分配给Executor
Executor:启动一个TaskRunner执行一个Task
二、Code转化为初始RDDs
我们的用户代码通过调用Spark的Api(比如:SparkSession.builder.appName("Spark Pi").getOrCreate()),该Api会创建Spark的上下文(SparkContext),当我们调用transform类方法 (如:parallelize(),map())都会创建(或者装饰已有的) Spark数据结构(RDD), 如果是action类操作(如:reduce()),那么将最后封装的RDD作为一次Job提交,存入待调度队列中(DAGSchedulerEventProcessLoop )待后续异步处理。
如果多次调用action类操作,那么封装的多个RDD作为多个Job提交。
流程如下:
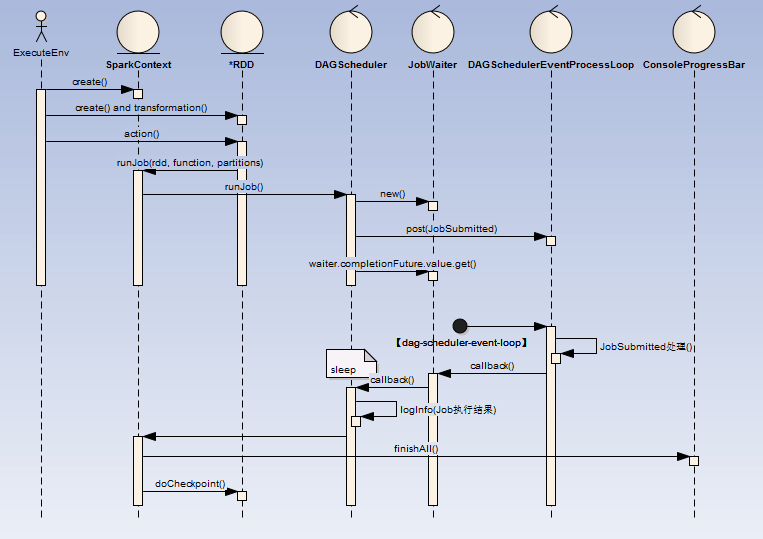
ExecuteEnv(执行环境 )
这里可以是通过spark-submit提交的MainClass,也可以是spark-shell脚本
MainClass : 代码中必定会创建或者获取一个SparkContext
spark-shell:默认会创建一个SparkContext
RDD(弹性分布式数据集)
create:可以直接创建(如:sc.parallelize(1 until n, slices) ),也可以在其他地方读取(如:sc.textFile("README.md"))等
延伸阅读
- ssh框架 2016-09-30
- 阿里移动安全 [无线安全]玩转无线电——不安全的蓝牙锁 2017-07-26
- 消息队列NetMQ 原理分析4-Socket、Session、Option和Pipe 2024-03-26
- Selective Search for Object Recognition 论文笔记【图片目标分割】 2017-07-26
- 词向量-LRWE模型-更好地识别反义词同义词 2017-07-26
- 从栈不平衡问题 理解 calling convention 2017-07-26
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明 2017-07-26
- Swift实现JSON转Model - HandyJSON使用讲解 2017-07-26
- 阿里移动安全 Android端恶意锁屏勒索应用分析 2017-07-26
- 集合结合数据结构来看看(二) 2017-07-26
 学习是年轻人改变自己的最好方式
学习是年轻人改变自己的最好方式