
二月份参加了蚂蚁金服商家技术部(杭州)的Java服务端后台开发面试,结果挂在了交叉面。之后仔细反思了一下,应该是缓存穿透这个问题导致的吧,当时太紧张回答成了工作中怎么使用一致性哈希+Redis解决远程分布式缓存负载均衡的,汗(⊙﹏⊙)b。
事后想找面试官再争取一下,无奈座机打不通,找客服说面试流程已经关闭了,只好暂时作罢。。 但是整个面试下来,收获很大,意识到了自己的一些不足,最遗憾的是没有和印象极其好极其好的一面和二面面试官一起工作的机会了,第一次面没有经验,花名都忘了问
了。。想想34岁还远着哪(呵呵),写代码的生涯还长,一次失败不算什么,楼主一定会回来的。
下面主要是写一下我实际工作中,解决的一个缓存数据量最大的场景的实现方案,以及怎么处理缓存穿透的。场景简单描述: 数据源是一张亿万条数据的DB Table,我要使用它在我们查询航班的API里匹配替换航班信息。实时读DB做增量Cache是肯定不行的,用这
张DB的人很多,DBA肯定会找上门的,另外会加大我们查询API的RT,最坏情况假如一个航班读一次DB做匹配替换,一个热门航线出现2000多个航段是家常便饭,再加上我们API的日均请求量已过半亿,所以我也不干。。于是综合讨论了之后,使用了如下的技术方案:
1. 数据源的存储 写一个定时任务,将DB的数据全量dump到Redis做分布式缓存
2. 数据源的获取 我们查询航班的API采用LRU+实时读取Redis补偿缓存
简单架构图如下:
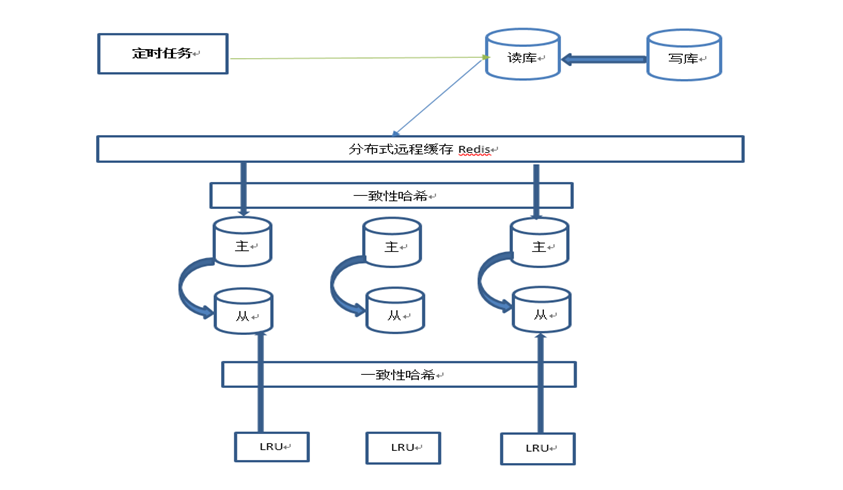
下面就到缓存穿透了,对我的这个场景来说就是指,LRU缓存未命中,导致大量的请求达到了Redis上。
目前我使用的最简单的方式就是,对不存在的Key,把Value置为null放到LRU中,来保护Redis。补充一句,如果采用的map结构不支持Value为null哪?(我个人是参考的Spring注册单例Bean的方式,生成一个叫nullObject的Object来标记null对象)
如果数据量再大或QPS更大,参考业界和查资料,有总结发现两个更好的方案来解决:
1.在LRU之前加一个布隆过滤器
2.倒排索引,将冷门数据dump到本地文件中
时间不早要下班撤了,就写这么多,有时间再总结分享下我采用的LRU的实现方式、一致性哈希和布隆过滤器等等,最主要的是代码,希望有大牛指点一下不足和更好的思路。
分类: 缓存技术
