
简介
前面两篇文章主要讲了数据库读写分离和分表分库的一些问题,这篇文章主要讲一下我个人实现的一个分表分库项目。
在此之前,我有写过一个.Net的分库,最近在做Java的项目,就顺便做出一个Java版本,这个项目源于我另外的一个业务项目,在这个业务项目中有分表(在一个数据库下有多张表),当时写了一套基于分表的帮助类,随着这个业务的的发展,基于分表的解决方案有一定的弊端,主要有两个:
1. 不能很好的扩展,在一个数据库下面有20张表,当业务繁忙的时候,数据库出现了压力(公司里面多个项目共用一个数据库服务器,有可能是其他项目影响了我的项目),这个时候想要扩展就比较麻烦了, 我可以将其中10张表迁移到另外的机器,同时我的代码路由算法就要改,其实将其中10张表迁移到另外服务器上,就已经类似于分库了。
2. 基于分表对业务的侵入性较高,我要先通过算法得到具体的表索引(即表的编号,比如user_15),然后要将整个索引和表前缀进行拼接才能得到真正的表名。
所以在开源分表分库的项目的时候,我对项目进行了升级,改为分库模式,即有多个数据库,每个数据库一张表,表名都一样,这样你就可以在mybatis中不需要再对表名进行修改。 降低了浸入性,同时也方便后续的扩展,你可以将这些数据库放在一台机器上,也可以在后续数据库服务器性能紧张的时候,将一部分数据库迁移到其他机器上。
最后说一下我当时为什么没有选择开源的解决方案,目前我知道的开源方案包括 sharding-jdbc ,mycat ,但是当时时间紧,任务重,研究熟悉部署这些项目,可能需要1-2天的时间,并且后续使用过程中,出了问题,还需要花时间排查,mycat 是基于分库的,所以并不适合我这个项目,而我的项目中,在操作数据库之前,已经可以知道具体要操作哪张表,对分表的操作也比较简单,但是要得到具体的表索引比较麻烦,是要经过多个key运算得到的,综合所有,我选择了自己写了一个。
项目介绍
项目比较简单,所有和分库相关的都在shardingcore中。 test是测试用的。

shardingcore的项目结构。
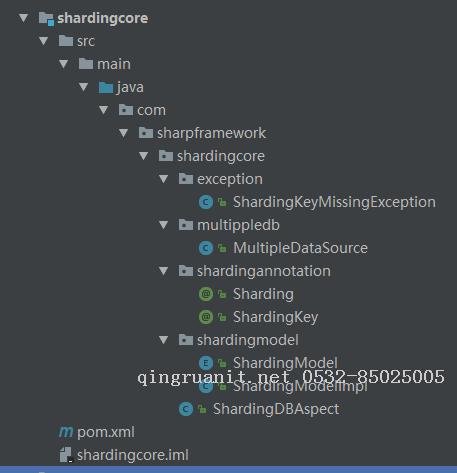
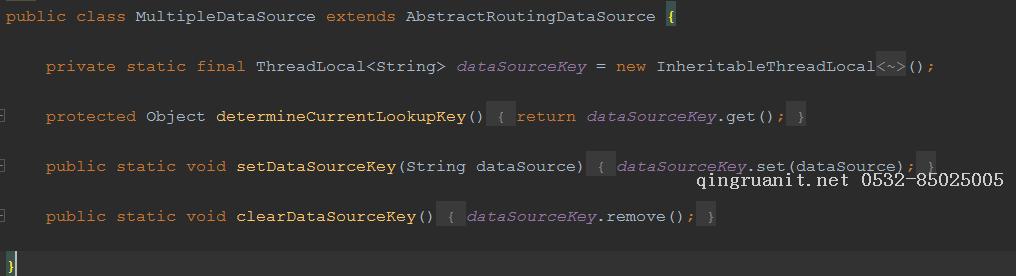
其中MultipleDataSource是为了实现切换数据库连接,这块代码是参考网上数据库读写分离的。
ShardingDBAspect是分库的核心代码。
