
1.简介
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
2. 算法大致流程为:
1)随机选取k个点作为种子点(这k个点不一定属于数据集)
2)分别计算每个数据点到k个种子点的距离,离哪个种子点最近,就属于哪类
3)重新计算k个种子点的坐标(简单常用的方法是求坐标值的平均值作为新的坐标值)
4)重复2、3步,直到种子点坐标不变或者循环次数完成
3.完整计算过程
1)设置实验数据
运行之后,效果如下图所示:

在图中,ABCDE五个点是待分类点,k1、k2是两个种子点。
2)计算ABCDE五个点到k1、k2的距离,离哪个点近,就属于哪个点,进行初步分类。
结果如图:
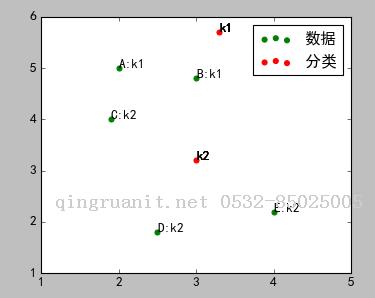
A、B属于k1,C、D、E属于k2
3)重新计算k1、k2的坐标。这里使用简单的坐标的平均值,使用其他算法也可以(例如以下三个公式)
a)Minkowski Distance公式——λ可以随意取值,可以是负数,也可以是正数,或是无穷大。